在大家一起玩libuv系列中间加入protobuf的基础教程是为了给我即将写的TcpServer做一个基本工作。TcpServer通信协议我打算使用protobuf来做,所以先讲讲protobuf怎样实现进程间通信的service吧。
1.安装
偷懒了,在mac上使用brew安装protobuf,版本是2.6.1.
brew install protobuf
根据官网的C++教程一步一步地使用protobuf。
2.编写proto文件
package communication;
option cc_generic_services = true;
message Void {
}
message Message {
required bytes content = 1;
}
service CommunicationService {
rpc send_message(Message) returns(Void);
}
3.生成C++文件
protoc --cpp_out=./ message_communication.proto
在本地生成了message_communication.ph.h和message_communication.pb.cc两个源文件。
4.使用
我们现在实现一个简单的应用。
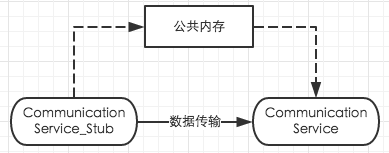
Stub发送端尝试去发送一个简单的字符串,接收端接收这个数据。其实发送端和接收端可以位于两个进程上,甚至两个不同的物理机上都可以,但这次用例展示主要适用于展示protobuf的使用,因此我们使用一个公共的内存用于两端的数据通信。所以上图中虚线才是真正的数据通路。
#include <iostream>
#include <sstream>
#include <string>
#include "proto/message_communication.pb.h"
struct StoreStruct {
int index;
std::string content;
};
static StoreStruct global_memory;
class ServiceChannel : public google::protobuf::RpcChannel {
public:
void CallMethod(const google::protobuf::MethodDescriptor *method, google::protobuf::RpcController *controller, const google::protobuf::Message *request, google::protobuf::Message *response, google::protobuf::Closure *done) {
global_memory.index = method->index();
std::ostringstream os;
if(request->SerializeToOstream(&os)) {
global_memory.content = os.str();
}
}
};
class MyCommunicationService : public communication::CommunicationService {
public:
void send_message(::google::protobuf::RpcController* controller,
const ::communication::Message* msg,
::communication::Void* rep,
::google::protobuf::Closure* done) {
std::cout << "receive data is " << msg->content() << std::endl;
}
void receive_data() {
const google::protobuf::MethodDescriptor *method = descriptor()->method(global_memory.index);
google::protobuf::Message* msg = GetRequestPrototype(method).New();
std::istringstream is(global_memory.content);
msg->ParseFromIstream(&is);
CallMethod(method, nullptr, msg, nullptr, nullptr);
}
};
int main()
{
communication::Message msg;
msg.set_content("I will send a message");
ServiceChannel service_channel;
communication::CommunicationService_Stub stub(&service_channel);
stub.send_message(nullptr, &msg, nullptr, nullptr);
MyCommunicationService receiver;
receiver.receive_data();
return 0;
}
首先创建一个Message,并且将Message的content变量赋值。之后利用Stub将数据传输出去。MyCommunicationService接收数据,并调用CallMethod方法,CallMethod会根据method的index调用对应的函数,这里就是send_message了。
5.后记
过大年我写博客也是蛮拼的了。